
Operator Hypotheses #7: Tidalwave
Testing whether a startup can own the user experience without owning the actual user record

About This Series
Operator Hypotheses tests one question: can you predict how a startup will fail or succeed before it happens?
Each entry picks one company, identifies the decision that will make or break it, and checks back 12 months later to see if the prediction held.
Pattern #7 looks at a specific trap in regulated industries. When a startup builds a new user experience on top of an old, entrenched system, does that experience become the place where real work happens? Or does the incumbent eventually bundle the startup’s features into its own product and squeeze it out?
Prior patterns covered services traps (Research Grid, DatologyAI), cascading early decisions (Chai Discovery), data custody and sales strategy (Flux), and the risk of becoming a high-touch delivery firm (Patronus AI). This pattern looks at the same question in mortgage which is one of the most locked-down technology markets in the U.S.
See Pattern #0 for the full framework.
The Problem That Didn’t Get Solved
Getting a mortgage is slow. According to Freddie Mac, the average mortgage takes 43 days to close. Each loan requires hundreds of manual steps across disconnected systems.¹ Despite years of supposed “digital transformation,” most of that work is still done by hand.
Here’s why. The mortgage industry actually automated the hard part — the credit decision — decades ago. Fannie Mae and Freddie Mac built software called Desktop Underwriter and Loan Product Advisor. These systems evaluate whether a borrower qualifies for a loan. Lenders trust them. Regulators accept them. They work.
But those systems can only run once a lender has gathered all the borrower’s financial documents: pay stubs, tax returns, bank statements, employment records. That collection process of finding, checking, and organizing all that paperwork is still mostly manual. That’s the bottleneck.
What changed in 2024 is that AI became good enough to read financial documents the way a human would. And Fannie Mae and Freddie Mac upgraded their systems to accept data directly from software, not just from humans typing things in.
That opened a window. Tidalwave positioned itself in that window.
But Tidalwave isn’t just a document-reading tool. The company describes itself as an agentic AI-powered mortgage point-of-sale platform - a full interface for borrowers and loan officers, with task lists, automated communication, multilingual support, and a white-labeled mobile app, all sitting on top of the existing mortgage software stack. The AI does the document work. The product surface does much more. That gap between what people assume Tidalwave is and what it actually is, is what this piece is about.
Why This Team
Tidalwave’s co-founders, Diane Yu, Jack Deng, and Cheng Li, built FreeWheel, an ad-tech company sold to Comcast in 2014. Two of the co-founders also worked at Better.com, the mortgage startup that raised over $900 million and tried to reinvent the home loan process.
Better.com failed not because its technology was bad, but because it tried to replace too much of the mortgage industry at once. Loan officers felt threatened. Lenders resisted. Regulators were skeptical. Better made its ambitions obvious before it had enough customers to protect itself.
FreeWheel’s experience is relevant for a different reason. Digital advertising and mortgage origination look nothing alike. But they share a structure: many parties, strict rules, large transaction volumes, and buyers who will never replace their core systems voluntarily. FreeWheel didn’t replace ad servers, it connected them. That instinct shows up in every decision Tidalwave has made.
The key insight behind Tidalwave: the mortgage bottleneck isn’t the credit decision. It’s getting clean data to the point where the credit decision can run. Lenders already trust Fannie Mae and Freddie Mac’s systems. What they don’t trust is whether the borrower’s documents are accurate and complete when those systems receive them. As Yu put it: “They don’t want AI to make the decision. They want AI to list the reasoning - where they got the information from, so that they can review and approve.”
That’s the gap Tidalwave fills. And the early results suggest it’s working. The platform is deployed across 3,200+ loan officers through the NEXA Mortgage partnership and is tracking toward 200,000+ loans by end of 2026. Flat Branch Home Loans, the first independent mortgage bank to use Tidalwave end-to-end, achieved a 90% application-to-submission conversion rate which is a strong number in a category where borrowers frequently abandon applications when they hit paperwork.
The Setup Most People Miss
Tidalwave made a strategic choice early on. It chose to work with the mortgage industry’s dominant software platform rather than against it.
That platform is Encompass, made by a company called ICE Mortgage Technology. Most mortgage lenders run their businesses inside Encompass. It’s where loans live, where compliance records are kept, and where the official paper trail exists. After acquiring rival Black Knight, ICE commands roughly 70% of the mortgage technology market. That’s an unusual level of concentration, even by enterprise software standards.
Tidalwave didn’t challenge Encompass. It became a partner. Tidalwave integrates with ICE/Encompass, MeridianLink, and Calyx Path through their existing APIs, with additional partnerships being negotiated. When a lender’s IT team evaluates Tidalwave, they don’t have to ask “will this break our Encompass setup?” The answer is no. Tidalwave connects to it.
That’s what made adoption politically easy. But here’s the thing: the product Tidalwave is building inside that safe position isn’t a narrow data-processing tool.
It’s a full experience layer. Borrowers use it to apply, upload documents, ask questions, and track their loan. Loan officers use it to manage their pipeline, handle tasks, and communicate with borrowers. Lenders can put their own brand on it with a white-labeled mobile app. It runs Fannie Mae’s and Freddie Mac’s underwriting checks simultaneously in the background.
These aren’t the features of a verification tool. They’re the features of a company that wants to become the place where mortgages happen while keeping Encompass around as the official record-keeper.
That’s the bet. And it’s already in motion.
The Fork
Tidalwave has already moved up the stack. The real question now is whether it can hold that position.
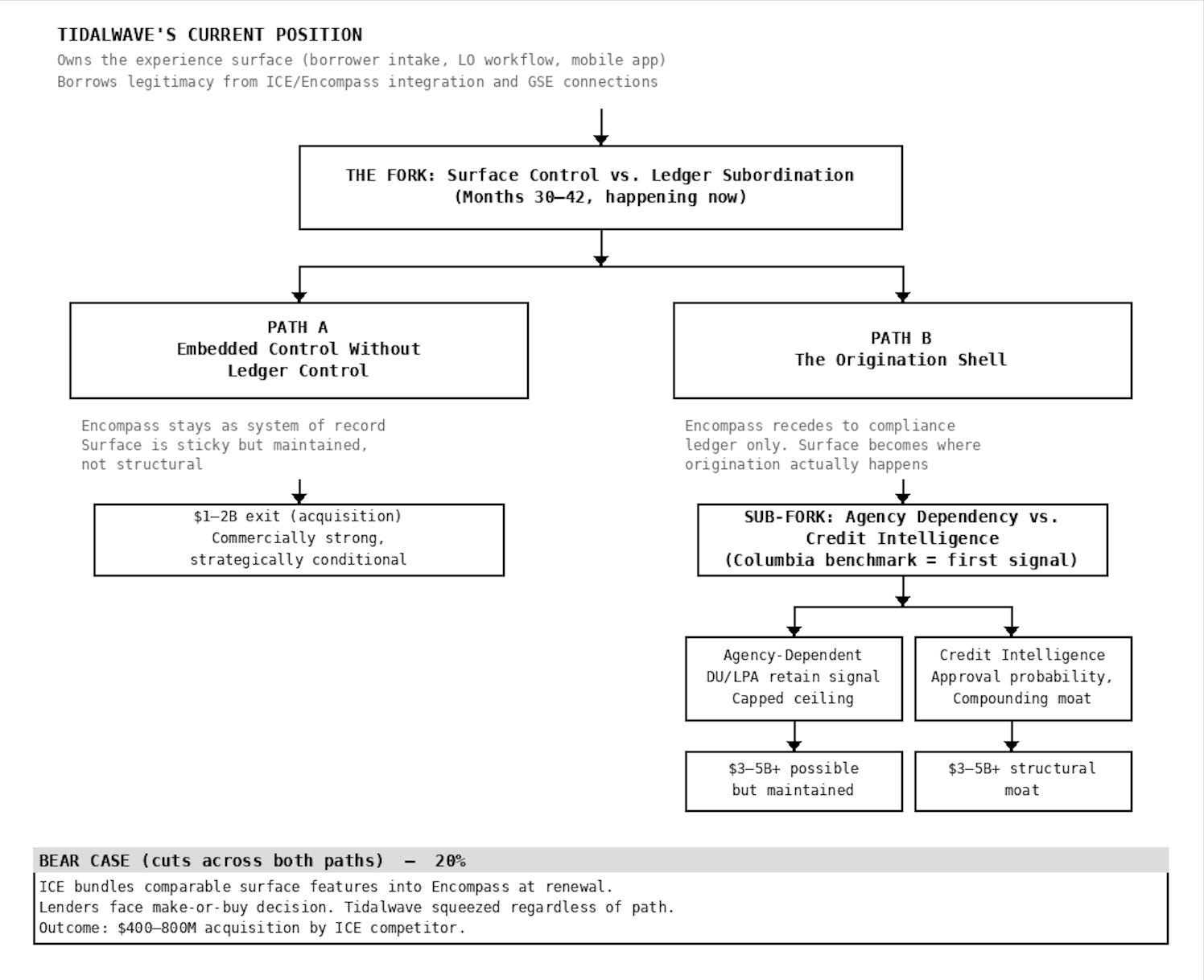
Fig.1. How Tidalwave's Early Choices Open Up or Constrain Its Ceiling
Path A: The Experience Layer
In this path, Tidalwave owns what borrowers and loan officers see and touch. The product is where people spend their time. But Encompass stays as the official system - the record, the compliance trail, the thing regulators and investors point to.
This is a real business. Lenders who train their teams on Tidalwave, build borrower experiences around its mobile app, and run their workflows through its platform develop real switching costs. Changing tools would be disruptive and expensive.
But it’s a position that has to be actively maintained, not one that protects itself. ICE controls the integration rules, the API terms, and the compliance credibility that lenders need. If ICE decides to build similar experience features and bundle them into Encompass, every lender faces the same question at contract renewal: why pay separately for something that now comes included? Tidalwave’s best answer of “our product is better” only works as long as the gap is obvious and worth paying for.
Path B: The Origination Shell
In this path, the experience becomes the infrastructure. Loan officers start their day in Tidalwave. Borrowers do everything through Tidalwave’s app. Encompass is still there in the background handling compliance records but it’s no longer where work happens. It becomes one of several integrations, not the host system.
Think of it like Stripe in payments. Stripe didn’t replace banks. It built the layer where transactions happen, and banks became the back-end plumbing. Mortgage is harder because one company controls 70% of the LOS market, regulations require specific systems of record, and the secondary market depends on standardized documentation. But the directional logic is the same.
To get here, Tidalwave needs loan officers to be so embedded in its product that switching would genuinely hurt - not just be inconvenient, but disruptive. That takes time and depth.
Borrowed legitimacy
There’s something underneath both paths worth naming. Tidalwave’s acceptance by conservative lender IT departments doesn’t come entirely from Tidalwave’s own reputation. It comes partly from the ICE relationship. Being part of the Encompass Partner Connect program signals that Tidalwave has been vetted. The GSE integrations signal that federal agencies have accepted the tool.
That’s borrowed legitimacy. It accelerates early adoption. But it’s also a ceiling: as long as Tidalwave depends on ICE’s endorsement to get through lender compliance reviews, ICE can change those terms. The goal — eventually — is to earn enough trust independently that the ICE relationship is a convenience, not a requirement.
The Data Question
This one matters only if Path B is happening. If Tidalwave stays as the experience layer, it gets skipped.
If Tidalwave becomes the origination shell, something interesting starts accumulating: data about how loans actually perform. Which applications pass Fannie Mae and Freddie Mac’s systems on the first try. Which ones get flagged for more documentation. Which borrower profiles trigger exceptions.
Over thousands of loans, that pattern becomes predictive. A platform with that data could tell a loan officer, before submitting anything: “Based on what we’re seeing, this borrower has a high chance of approval” or “this documentation is likely to get flagged.” That kind of pre-underwriting intelligence would be very hard for a competitor to replicate.
Whether Tidalwave is building toward that is not fully visible from outside. What is visible: in March 2026, Tidalwave published a benchmark with Columbia University showing its mortgage-trained agent outperforming general-purpose LLMs on underwriting and compliance tasks - 84% overall accuracy vs. 71% for Claude 4.5, with the largest gap on yes-or-no compliance checks.
The choice to validate externally through an academic partner rather than make internal accuracy claims reflects the same borrowed legitimacy logic that shaped the ICE integration: credibility through association before credibility on its own terms. This is an early signal that the credit intelligence path is already being tested. One study on synthetic loan files is not a compounding data moat but it is no longer a purely hypothetical future direction.
There’s a regulatory wrinkle here. Lenders are required to explain credit decisions under federal fair lending law. Any system that influences those decisions - even before formal underwriting runs needs to be explainable. Tidalwave’s current position (”we surface information, humans decide”) keeps it on the safe side of that line. The tension is that the most durable version of Path B probably requires crossing closer to that line. How Tidalwave handles that when it arrives will matter.
D.R. Horton as a Signal
D.R. Horton is both an investor in Tidalwave and a customer. Its mortgage subsidiary, DHI Mortgage, originated 71,000 mortgages worth $24 billion in 2024. The next-largest homebuilder lenders — Lennar Mortgage at $20 billion and Pulte Mortgage at $8.3 billion² — are direct competitors of D.R. Horton.
The question: will those competing lenders adopt Tidalwave, knowing D.R. Horton has an equity stake and production access?
If Lennar or Pulte signs with Tidalwave by April 2027, the answer is: they don’t see the D.R. Horton relationship as a problem. The platform reads as neutral infrastructure, like a utility. That’s a signal that Path B is plausible.
If the customer base stays concentrated in independent mortgage banks and brokers with no competing homebuilder lenders two explanations are possible. Either perception risk is real, or Tidalwave simply doesn’t need that segment. Telling those two apart is itself informative.
Three Scenarios
Base Case (50%): The Experience Layer Holds
Tidalwave becomes how borrowers and loan officers interact with the mortgage process at a growing number of lenders. Encompass stays as the official system underneath. Customers describe Tidalwave as the tool they use, Encompass as the system that records everything.
The product keeps getting better at the experience — faster communication, cleaner document handling, better task management. No direct move against Encompass’s core functionality.
Customer growth comes mostly from independent mortgage banks and mid-size lenders. No competing homebuilder subsidiary signs up.
This is a real business. Sticky customers. Clear exit paths. But the position has to be actively maintained. Every renewal cycle is a test. The race between Tidalwave’s depth and ICE’s response is what determines the outcome.
Series B: $60–90M. Multiple: 12–16x ARR. Likely exit: $1–2B acquisition by ICE, a fintech platform, or a large lender.
Bull Case (30%): The Origination Shell
The experience becomes dominant. Loan officers don’t open Encompass first. Borrowers don’t know they’re using anything except their lender’s branded app. Encompass is compliance infrastructure — important, invisible.
Case studies start saying “we rebuilt our origination process around Tidalwave” instead of “we added Tidalwave to our Encompass workflow.” That’s a different sentence. It describes a different relationship.
If credit intelligence features show up — approval probability, documentation gap scoring — the data moat is forming. A competing homebuilder lender signs.
Series B: $100–150M. Multiple: 18–25x ARR. Outcome trajectory: $3–5B independent platform. The only scenario that gets to category scale.
Bear Case (20%): ICE Moves First
ICE builds comparable experience features and bundles them into Encompass. The pitch to lenders: why add a third-party tool when your LOS now does the same thing?
Lenders don’t have to say Tidalwave is worse. They just have to decide that the difference isn’t worth a separate contract. ICE controls roughly 70% of the market and has been explicit about its ambition to cover the full life of a loan. At 40 employees and $24M total raised, sustaining a clear product gap against ICE’s engineering resources is hard.
Customer acquisition slows. Series B happens at lower terms, or the company enters acquisition talks earlier than planned.
Likely exit: $400–800M to an ICE competitor that needs workflow automation to compete.
What to Watch
All of these signals are visible from outside — no insider access needed.
By mid-2026: What’s in the product?
Signs pointing toward the origination shell:
A standalone borrower intake tool that isn’t embedded inside another POS product
Loan officer pipeline management that lives in Tidalwave, not inside Encompass
Job postings for workflow engineers and product designers focused on loan officer tools
Signs pointing toward the experience layer:
Product updates about new data integrations and verification improvements
Expanded partnership with ICE through new Encompass features
No standalone loan officer pipeline product
By fall 2026: How do customers describe it?
This is the most important signal of all — not what Tidalwave says about itself, but what customers say.
Shell language: “We rebuilt our origination process around Tidalwave.” “Our loan officers start their day there.” “Encompass handles the records; Tidalwave is where the work happens.”
Experience layer language: “We added it to our Encompass workflow.” “It integrates with our existing tools.” “It made verification faster.”
Watch also for: predictive product features (approval probability, documentation gap alerts) and any competing homebuilder lender deployment.
By early 2027: The Series B tells the story
The type of investor leading the round, the valuation multiple, and the press narrative will each independently confirm which path is forming. Read them together.
One final test: can a loan officer start their workday inside Tidalwave without opening Encompass for the first hour? The answer to that question is more informative than any press release.
What Would Prove This Wrong
The main falsifier: By April 2027, customers and press still describe Tidalwave as an Encompass add-on — useful, but not the place origination actually happens. If lender case studies and loan officer testimonials consistently frame it as a verification enhancement rather than a primary working environment, the origination shell thesis fails.
Note: companies often describe their tech tools conservatively in public, especially in regulated industries. Where public language and product architecture conflict, trust architecture. The behavioral test — where work actually happens — is more reliable than what the communications team says.
The secondary falsifier: If ICE expands its Partner Connect program to support Tidalwave more deeply, and doesn’t build competing features, the bundling threat is weaker than estimated.
Other things that could break the prediction:
Tidalwave stays as the experience layer but still builds proprietary credit intelligence — proving that the two questions are separable
AI-native lenders switch infrastructure faster than expected, making the path to the origination shell shorter than 12 months
ICE’s partner ecosystem endorsement becomes a liability instead of an asset, because lenders specifically want tools that aren’t connected to ICE
Industry-specific risks:
Mortgage’s compliance requirements force so much lender-specific customization that Tidalwave slides into services work not yet visible in public signals
Federal regulators reclassify AI-assisted origination workflows as credit decision tools, requiring product changes regardless of strategy
What this analysis can’t see: Tidalwave hasn’t disclosed revenue, margins, full customer count, or the terms of the D.R. Horton deal. Everything here is inferred from public signals. If the actual numbers tell a different story, that changes the prediction.
A Note on This Market
The mortgage LOS market is more concentrated than any vertical examined in this series. Following its acquisition of Black Knight, ICE commands roughly 70% of the mortgage technology market — a figure cited by HousingWire based on ICE’s own investor communications. That level of concentration makes the fork here structurally different from similar situations in other industries. It’s not just that the incumbent is large; it’s that replacing it requires navigating regulatory continuity rules, compliance audits, and secondary market documentation standards simultaneously.
ICE’s behavior also makes the containment scenario grounded rather than theoretical. The company has a track record of absorbing or retiring partner-adjacent products as it builds toward a unified system. It announced the retirement of its legacy Encompass SDK — originally targeting October 2025, extended to December 2026 — in favor of the Encompass Partner Connect API framework.³ It also launched a program to retire the legacy Encompass CRM in favor of its Surefire product.⁴ The pattern is consistent: ICE consolidates toward a single stack, and independent tools that overlap with that stack face pressure over time.
Check-back: April 2027.
Pattern tracking:
Pattern #1: Research Grid (Month 11) — Services trap prediction — Check-back April 2026
Pattern #2: DatologyAI (Month 25) — Services trap verification — Check-back October 2026
Pattern #3: Chai Discovery (Month 20) — Compound fork effects — Check-back October 2026
Pattern #4: Flux (Month 29) — GTM lock-in — Check-back January 2027
Pattern #5: Patronus AI (Month 29) — Authority-driven services gravity — Check-back February 2027
Pattern #6: Charm Security (Month 15) — Regulatory authority drift — Check-back February 2027
This is pattern research testing whether execution forks are predictable from public signals. It is not investment advice. Predictions will be evaluated April 2027.
References
[1] Tidalwave. (2025). “Building the Future of Mortgage Technology: Our $22M Series A.” Blog post. 43-day figure sourced via Freddie Mac, https://myhome.freddiemac.com/buying/closing-your-loan-when-buying. “Hundreds of manual tasks” language appears in the same post. https://www.tidalwave.ai/blog/series-a-announcement
[2] HousingWire. (2025). “Here are the top 25 mortgage lenders of 2024, per HMDA.” April 3, 2025. Pulte Mortgage $8.3B figure sourced from iEmergent data reported by Inman, November 21, 2025. https://www.housingwire.com/articles/here-are-the-top-25-mortgage-lenders-of-2024-per-hmda/
[3] HousingWire. (2025). “ICE delays Encompass SDK transition until end of 2026.” August 18, 2025. https://www.housingwire.com/articles/ice-delays-encompass-sdk-transition-until-end-of-2026/
[4] HousingWire. (2024). “ICE launches pilot to sunset old Encompass CRM.” October 3, 2024. https://www.housingwire.com/articles/ice-launches-pilot-to-sunset-old-encompass-crm/
[5] HousingWire. (2024). “Why ICE’s move away from SDKs in 2025 is a win for the mortgage industry.” December 9, 2024. https://www.housingwire.com/articles/why-ices-move-away-from-sdks-in-2025-is-a-win-for-the-mortgage-industry/
[6] HousingWire. (2026). “Tidalwave company profile.” February 2, 2026. https://www.housingwire.com/company-profile/tidalwave/
[7] National Mortgage Professional. (2025). “NEXA Mortgage Deploys Tidalwave’s Agentic AI Platform Enterprise-Wide.” August 12, 2025. https://nationalmortgageprofessional.com/news/nexa-mortgage-deploys-tidalwaves-agentic-ai-platform-enterprise-wide
[8] HousingWire. (2026). “Flat Branch Home Loans launches AI mortgage app with Tidalwave.” February 2026. https://www.housingwire.com/articles/flat-branch-tidalwave-mortgage-ai/
[9] Tidalwave. (2025). “Agentic AI is turning into the next big mortgage trend.” Blog repost of National Mortgage News interview with Diane Yu. https://www.tidalwave.ai/blog/national-mortgage-news-agentic-ai-is-turning-into-the-next-big-mortgage-trend
[10] Tidalwave. (2025). “SOLO — The Only Agentic AI Mortgage POS+.” Product page. https://www.tidalwave.ai/
[11] Fortune. (2025). “Tidalwave raises $22 million Series A to improve the mortgage process with AI.” November 21, 2025. https://fortune.com/2025/11/21/tidalwave-raises-22-million-series-a
[12] Business Wire. (2025). “Agentic AI Mortgage Startup Tidalwave Partners with First Colony Mortgage and Mortgage Solutions.” May 13, 2025. https://www.businesswire.com/news/home/20250513208178/en/
[13] HousingWire. (2023). “ICE solidifies position as the dominant player in the mortgage tech space in 2023.” https://www.housingwire.com/articles/ice-solidifies-position-as-the-dominant-player-in-the-mortgage-tech-space-in-2023/
[14] Freddie Mac. (2024). “Cost to Originate” study. Referenced in Tidalwave Series A materials. https://sf.freddiemac.com/docs/pdf/cost-to-originate-full-study-2024.pdf
For me, the most striking comment: "Tidalwave published a benchmark with Columbia University showing its mortgage-trained agent outperforming general-purpose LLMs on underwriting and compliance tasks - 84% overall accuracy vs. 71% for Claude 4.5, with the largest gap on yes-or-no compliance checks."
Tidalwave built its own specially trained agent, and it only outperformed a 2-generation-old Claude model (w/ undetermined thinking intensity) by a bit. How will 4.6 and 4.7 perform? What about 5.0? What about 5.0 w/ grounding skills and context?
The one lesson from the past 2 years is that verticalized AI gets clobbered on quality by rapid improvements in foundation models and on cost by rapid improvements in open weight/open source models.
This is not the space I'd want to compete.